显卡用纸折法有哪些?如何折出好看的显卡纸模型?
3
2025-08-03
随着人工智能领域的飞速发展,深度学习模型(DL)已经成为科研与商业应用中的重要工具。DFL(DeepFeatureLearning,深度特征学习)模型在图像识别、语音处理等众多领域表现出色。然而,进行DFL模型训练需要特定的硬件支持,尤其是显卡。在本文中,我们将探讨DFL模型训练对显卡的具体要求,并提供一些实用的选购建议。
在开始探讨具体的显卡性能要求前,先要明确几个核心要点:
并行处理能力:DFL模型训练通常需要大量的并行计算,GPU在这一点上具有先天优势。
内存容量:深度学习模型往往需要大量内存来处理大规模数据集。
计算精度:高计算精度能够确保模型在训练过程中的数值稳定性。

1.GPU核心数
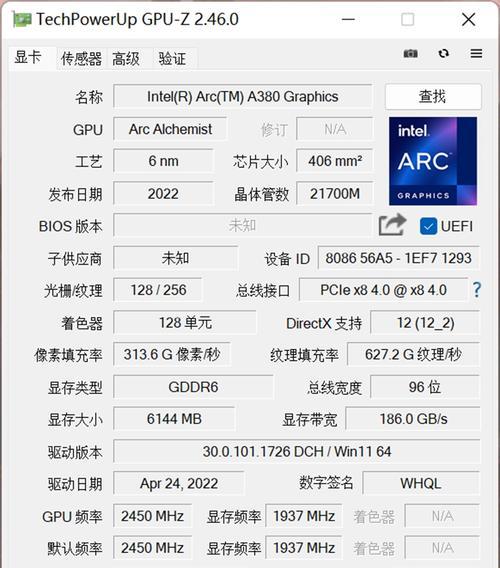
高核心数的显卡能有效提升模型训练速度。对于入门级的DFL模型,使用具有千核心以上GPU的显卡就已足够;但对于更加复杂和庞大的模型,如VGG、ResNet等,可能需要万级核心数的显卡,例如NVIDIA的RTX系列显卡。
2.显存大小
显存是存储训练数据和中间计算结果的重要资源。一个基本的经验法则是:至少需要4GB显存来训练小型模型,而对于大型模型来说,建议使用至少16GB甚至更高的显存。一些顶级的显卡,如RTX2080Ti和TeslaV100,提供了32GB甚至更大的显存,可以很好地应对复杂的DFL模型训练需求。
3.计算精度和速度
DFL模型训练中常见的浮点运算包括FP32和FP16(半精度浮点数)。FP16虽然提供了更快的计算速度,但FP32能够提供更精确的结果。选择支持FP32或混合精度计算的显卡通常更有利于模型的稳定训练。
4.显卡品牌和型号选择
目前在DFL模型训练领域,NVIDIA的显卡以其对CUDA和cuDNN等优化库的良好支持而占据主导地位。GTX系列适合入门和中级需求,而RTX系列则在高级研究和商业应用中得到广泛使用。AMD显卡虽然在性价比上有一定优势,但在深度学习领域的支持和优化上可能不如NVIDIA。
1.实用技巧
多显卡并行:利用多显卡并行可以显著提升训练速度,NVIDIA的NVLink技术可实现高效的数据传输。
云端GPU资源:如果本地硬件资源有限,可以考虑使用云计算服务,如AWSEC2、GoogleCloudPlatform等提供的GPU实例。
2.常见问题
如何估算显卡需求:根据模型大小、数据集规模、所需精度和训练时间等要求进行综合评估。
显卡升级对模型性能的提升有多大:显卡性能的提升可以缩短训练时间,但对模型性能的影响有限。关键是数据质量和算法本身。

选择合适的显卡对于DFL模型训练至关重要。随着技术的进步,显卡的性能和功能也在不断增强。了解并选择适合您模型需求的显卡,能够有效提升训练效率和模型质量。希望本文对您在选购显卡和进行DFL模型训练时提供有价值的参考。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。